高速かつ大規模なデータ統合
データ ソースとユーザー データが急増する中、多くの組織はさまざまなユース ケースのデータの準備と提供に必要な時間に圧倒されています。今日のビジネスの世界ではスピードが不可欠であり、デジタルに精通した企業はコラボレーションを強化し、誰もがすぐに利用して行動できる形式でデータ主導の洞察を提供することで成功を収めています。
Trianz では、組織が AWS Glue を使用してレガシーシステムを変革するための、拡張性とコスト効率に優れたソリューションを見つけられるよう支援することを目指しています。AWS アドバンスト パートナーとして、当社の AWS Glue 機能には以下が含まれます。
AWS Glue のベストプラクティスを使用して安全なデータパイプラインを構築およびデプロイする
Glue データカタログ、Lake Formation、DataOps、およびキー管理サービス (KMS) を使用したデータセキュリティのセットアップと実装
レガシー ETL ワークロードを AWS Glue に移行する
エンタープライズ PaaS 環境とそのデータ ポートフォリオを統制された方法で運用および管理する

ユースケースに関係なく、当社の専門チームは、今日の最も厳しいデータ、ペルソナ、アプリケーションの障壁を克服するために必要なコラボレーション文化を組織に提供します。
AWS Glue とは何ですか?
2017 年に ETL サービスとして始まり、データ準備ツールへと進化した AWS Glue は、現在では世界中の何十万もの組織で使用されている本格的なデータ統合サービスとなっています。AWS Glue はサーバーレス環境で実行されるため、サーバーのプロビジョニング、構成、起動は不要で、ユーザーは使用した時間に対してのみ料金を支払います。
従量課金モデルとペタバイト規模のデータ量を統合する機能により、Glue は安全でスケーラブルなデータ レイク、ウェアハウス、レイクハウス、データ メッシュ アーキテクチャを構築するための選択肢として急速に人気が高まっています。
AWS Glue の利点

サーバーレス
維持するインフラストラクチャはなく、Glue は必要な計算能力を自動的に割り当ててジョブを実行します。

コスト効率が良い
Glue のオールインワン価格モデルは、他のクラウド データ統合オプションよりも 55% 安価です。

ロックインなし
ユーザーは、SparkSQL、PySpark、Scala を使用してオープンソースでデータ統合パイプラインを開発するオプションがあります。
マルチインターフェース
開発環境は、データ エンジニア向けのビジュアル ETL 開発、データ サイエンティスト向けのノートブック スタイルの開発、データ アナリスト向けのノーコード開発など、さまざまなスキルセットに合わせて提供されています。
複雑なワークロードを処理
200 を超えるデータ ソースに接続し、バッチ、ストリーミング、イベント、インタラクティブ API ベースの実行モードを使用してペタバイト規模のデータを処理します。
AWS Glue のケーススタディ

機械学習の有効化
大手グローバル小売チェーンは、顧客ロイヤルティの向上とデジタル販売の拡大のために、オムニチャネル販売およびマーケティング分析と顧客 360 分析を導入したいと考えていました。従来のデータと分析プラットフォームを AWS 上の最新のクラウド アーキテクチャに移行する必要がありました。
Trianz が AWS Glue を使用して機械学習のユースケースを実現し、顧客の行動をより深く理解できるようにした方法については、グローバル小売チェーンのデジタルマーケティング業務の変革に関するこのケーススタディをお読みください。

クラウド分析ソリューション
大手グローバル医療サービス提供会社は、クラウド インフラストラクチャを活用して、安全でスケーラブルな業界準拠のクラウド IT プラットフォームを構築したいと考えていました。米国と EU の地域における医療に関する洞察を生成するために、最新の高度に準拠した分析機能が必要でした。
Trianz が AWS Glue を使用して、厳格なガイドラインと規制に準拠した柔軟でスケーラブルかつ安全な分析プラットフォームを構築した方法については、 AWS クラウドでのグローバルデータプラットフォームの構築に関するこのケーススタディをお読みください。
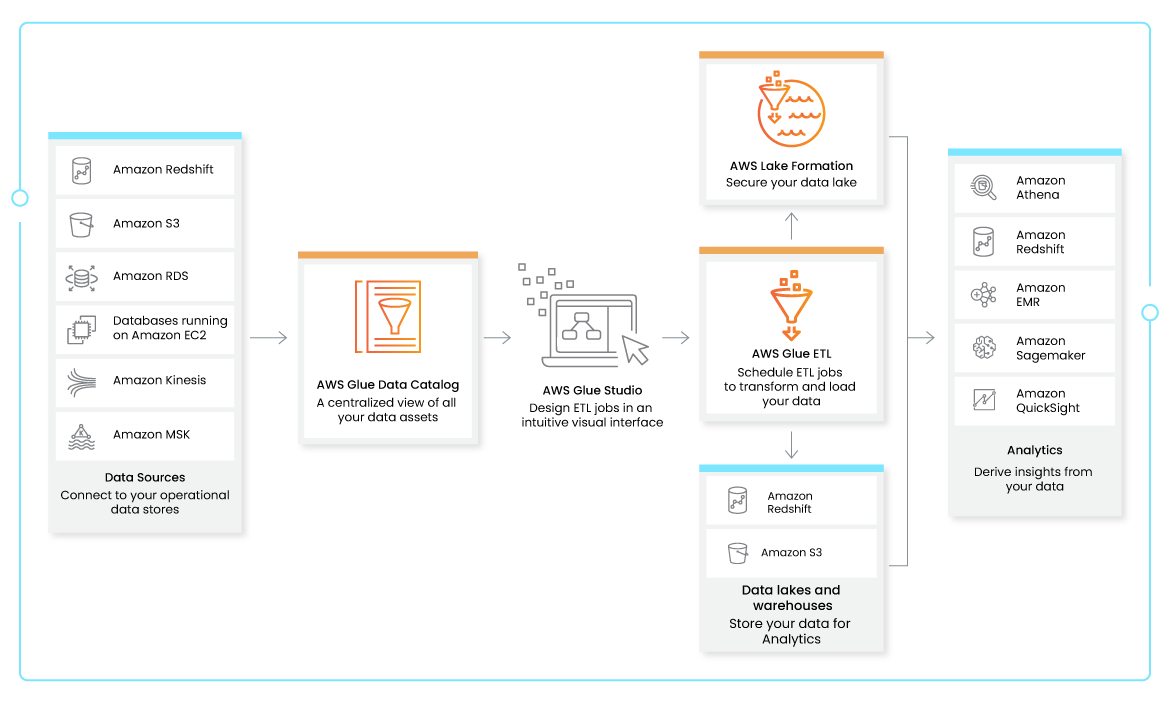
AWS Glue のユースケース
電子商取引
Glue は、抽出、変換、ロード (ETL) サービスとして、わかりやすい UI ベースの環境で複雑な ETL ワークフローを開発するために使用されます。3 つのビジュアル インターフェイスが提供されており、データ エンジニア、ETL 開発者、アナリストは、追加のコーディングをほとんどまたはまったく必要とせずに ETL ワークストリームを作成できます。
ユーザーは、AWS Glue データカタログのテーブル定義を使用してジョブを作成し、ジョブを開始するトリガーを設定し、クローラーをソース方向に向け、データを取得するだけで、Glue はソースからターゲットにデータを変換するために必要なコードを自動的に生成します。Glue の 3 ステップのプロセスにより、ユーザーは ETL ジョブを数か月ではなく数分で完了できます。
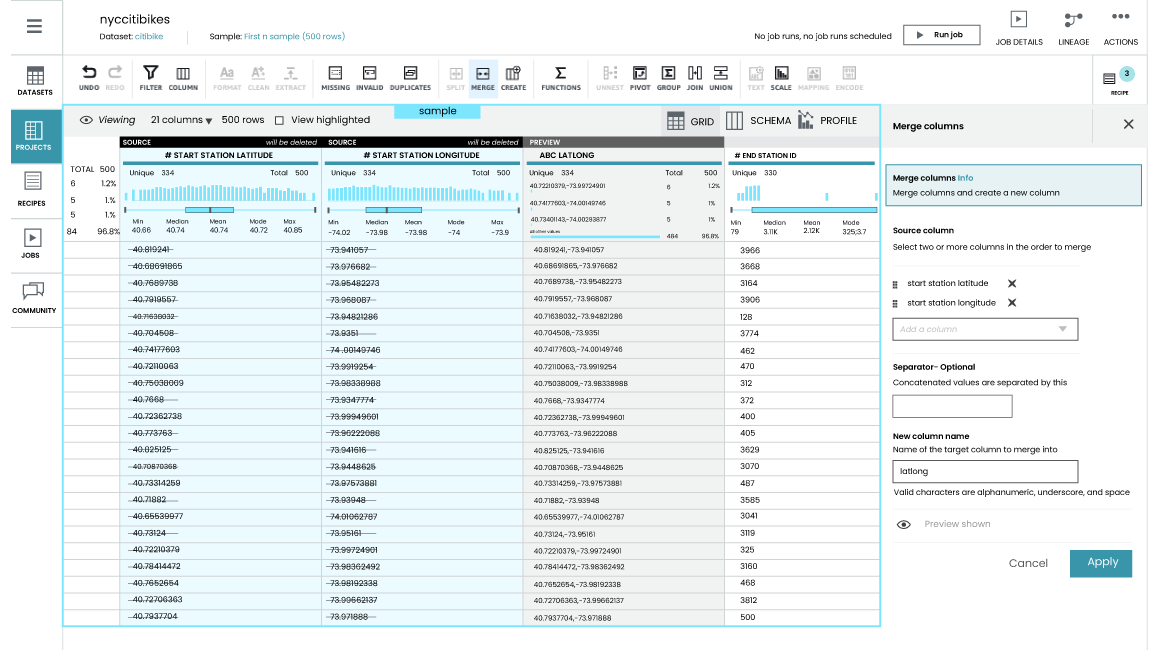
データ準備
AWS Glue は、データ サイエンティストがデータを簡単にクリーンアップおよび正規化できるようにする視覚的なデータ準備ツールである DataBrew を使用して、データ準備を効率化します。ユーザーは、分析や機械学習に適した形式にデータを自動的に変換できる 350 を超える事前構築済みの変換から選択できます。事前の契約は不要で、ユーザーは DataBrew の使用時間に対してのみ料金を支払います。
データ統合
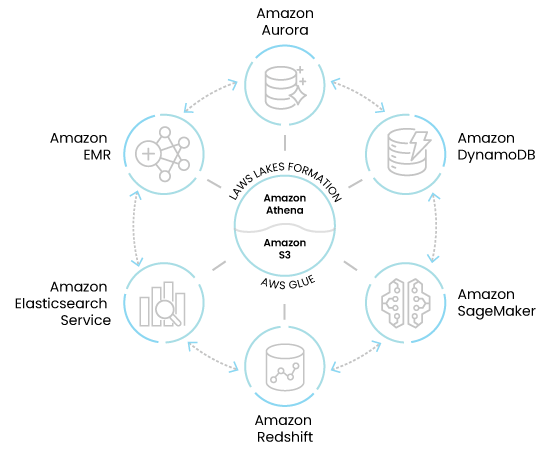
AWS Glue と AWS Lake Formation は、データレイクとレイクハウスを構築するための必須コンポーネントです。Glue は、AWS サービス間でのシームレスなデータ移動のためのデータカタログとクローラーを提供します。AWS Lake Formation を使用すると、データをデータレイクまたはレイクハウスとして一元管理、キュレーション、保護できます。簡単に言うと、AWS Lake Formation はセキュリティとガバナンスのためのきめ細かなアクセス制御を提供し、AWS Glue はデータレイク分析のためのメタデータとデータ検出を簡素化します。最終的に、ユーザーはコスト効率が高く、適切に管理され、高度にスケーラブルなデータストアソリューションを手に入れることができます。